RAG是什么,它如何解决大模型“幻觉”问题?
RAG是什么,它如何解决大模型“幻觉”问题?
作者:航标
来源:航标IT精选
|
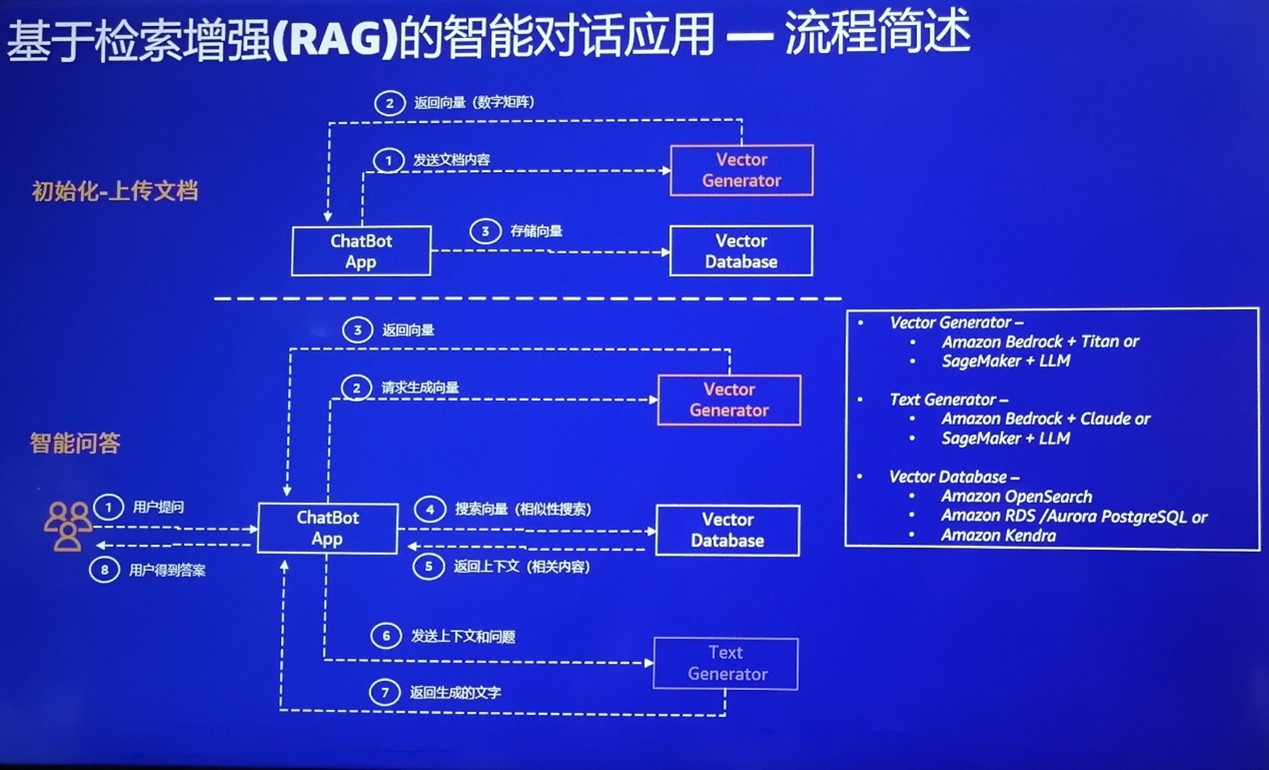
ChatGPT的成功点燃了人们对生成式AI的热情,各种生成式 AI的应用如雨后春笋般涌现出来。然而,那些基于通过大语言模型(LLM)的生成式AI应用都会面临一个挑战——幻觉,也就是人们常说的“一本正经地胡说八道”。为了克服大语言模型的“幻觉”,人们想了不少办法,比如微调(Fin-tuning)、提示工程、检索增强生成(Retrieval-Augmented Generation,RAG)等,其中,RAG被认为是最有前途的技术之一,已被广泛应用于知识问答、文档检索等生成式AI应用中。 幻觉是如何产生的所谓的“幻觉”是指大语言模型的输出看起来很正常,但与事实不符,或者完全就是胡说。背后的原因在于,本质上大语言模型生成的内容是基于统计、基于概率的,是非确定性的。 大语言模型使用的是被称为深度学习的复杂计算过程来识别大量数据中的模式,其核心技术是神经网络,它模拟人脑处理和解释信息的方式,根据后面出现单词的可能性来生成文本,生成的文本通常遵循语法和语义规则,但这仅仅满足统计上的一致性。 大语言模型虽然给人一种很智能的感觉,似乎能理解我们所说的话,而事实上它从来没有真正理解,也不可能真正理解。大语言模型的生成结果取决于它所训练的数据,其幻觉主要是数据集和训练的缺陷造成的。 比如,训练数据的错误标签和错误分类可能导致幻觉,如果有偏见的数据或缺乏相关数据也可能会导致模型的输出看似准确,但可能被证明是有害的。 另外,当模型对训练数据(包括噪声和异常值)学习得很好时,就会发生过度拟合。模型复杂性、训练数据有噪声或训练数据不足都会导致过度拟合,从而引来低质量的模式识别,并妨碍模型被应用到新数据,最终导致分类和预测错误、不正确的输出或彻彻底底的幻觉。 克服大语言模型的幻觉有多种方法可以解决大语言模型的幻觉问题,比如,微调(Fin-tuning)、提示工程和RAG等。 微调是指使用特定领域的数据集重新训练模型,以更准确地生成与该领域相关的内容。然而,重新训练或微调模型需要时间,如果不持续训练,数据很快就会过时。另外,由于大语言模型涉及参数规模越来越大,数据量也越来越多,即使微调也需要很大的投入。 提示工程是通过在大语言模型的输入中提供更具描述性和更明确的信息作为提示,为模型提供额外的知识,以此来帮助大语言模型产生高质量的结果。这对于提示的生成提出了比较高的要求,在知识库这类场景中效果不太理想。 和微调和提示工程相比,RAG 提供了一种低成本、高收益的替代方案。RAG借助外挂的知识库来为大语言模型提供准确和最新的知识,以提升大语言模型生成内容的质量,减少错误内容的产生。 RAG允许对新增数据部分使用相同的模型处理,而无需调整及微调模型,从而极大地拓展了大模型的可用性。这就相当于让知识库在不影响访问速度的前提下,拥有了近乎无限的可扩展性。 实际上,RAG除了解决大模型的幻觉之外还有其他重要的能力。比如,可以保护用户的私域数据,避免数据外泄。自从ChatPat发布以来,已经有多起因为敏感信息被以提问的方式输入到ChatGPT中,导致相关内容进入学习数据集,最后泄漏给其他人的事件发生。而RAG中外挂的知识库不会进入大模型被用于学习和训练,因而也就不会泄露给其他用户。另外,RAG还可以通过外挂知识库的更新来解决大模型数据的实时性不够的问题。 由于RAG的上述特性使其成为很多公有云服务商主推的两种生成式AI服务框架(另一个是Agents)。比如,百度云现在主推的生成式AI框架就是RAG和Agents。在不久前的百度世界2023大会上,百度云负责人沈抖在大会演讲时就演示了RAG的一个例子:先通过百度云的千帆开发平台导入三一重工的一种挖掘机长达48页、2万多字PDF格式的使用说明书,并建立关联,然后将该平台自动生成的一段代码拷贝到三一重工官网的代码中。仅仅几步,该官网就具有智能问答的能力。其不仅具有了百度文心通用大模型的理解能力,还能为三一重工的官网提供具体到这款挖掘机如何使用的答复,比如这款挖掘机使用什么冷却液。显然,只靠通用大模型是无法回答这么专业的问题的。 RAG是如何工作的RAG 有两个重要的组成部分:预训练的基础模型和外挂的专业知识库。这个知识库中含有回答问题所需的专业知识和确保答案正确的各种规则。 基于RAG的智能应用投入工作之前需要先建立这个知识库。知识库可以有很多形式,比如,向量数据库、知识图谱,甚至可以直接把ElasticSearch数据接入。其中,向量数据库因为具备对高维向量的检索能力,和大模型的结合简单,效果最好,目前也是 RAG 中最为常用的外部数据源。 一般而言,为了创建向量数据库,需要先将文档进行切片,进行向量化,然后存储到向量数据库中。这个切片大小以及切法会影响将来数据检索的效果,也是优化的关键环节。值得一提的,这里的向量数据库并非一定是专业的向量数据库,也可以是支持向量搜索引擎的通用数据库,如带有pgvector插件的 PostgreSQL数据库。 基于RAG的智能问答应用接到用户问答后会先将问题转换为向量,然后检索外挂知识库,从中找到与用户问题相关的内容,再与问题进行合并做嵌入(Embedding),然后输入给大语言模型,最后由大语言模型根据自己的认知,做出回答。如下是AWS基于RAG的智能对话流程。
结束语今天,生成式AI已经广泛用于写文章、做摘要、进行总结等,但要进一步普及,特别是在生产场景中得到应用,还需解决其正确性和可靠性问题。比如,在医疗保健、金融或法律服务等关键领域可靠的准确性就至关重要。RAG从大规模的知识库中精确地抽取信息,并生成富有洞察力可解释的答案。这种能力使得RAG超越了传统的检索方法,无疑将加速生成式AI在更多领域尤其是关键生产领域的普及。 |
 商情
商情


