AWS 正在开发基于大模型的数据库调试器
AWS 正在开发基于大模型的数据库调试器
作者:开源爱好者
来源:
|
AWS 研究人员发表了一篇论文,针对 OpenAI 的 GPT-4 提出了一个基于 LLM 的专有调试器(被称为 Panda)。
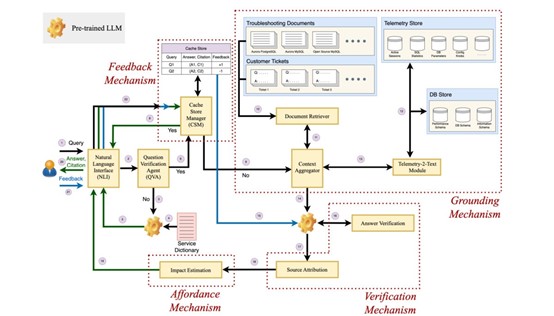
AWS 研究人员正在为数据库开发基于大型语言模型的调试器,以帮助企业解决数据库的性能问题。 该公司在一篇博客中写道,新的调试框架被命名为Panda,其工作方式类似于数据库工程师(DBE),并补充说,排除数据库中的性能问题通常“格外困难”。 与负责管理多个库的数据库管理员不同,数据库工程师的任务是设计、开发和维护数据库。 研究人员解释说,Panda实际上是一个框架,它为预先训练好的LLM提供上下文基础,以便生成更加“有用”和“符合上下文”的故障排除建议。 Panda的组件和架构 该框架包括四个关键组件:训练、验证、承受能力和反馈。 研究人员将验证描述为模型能够利用相关来源验证生成的答案,并在输出的同时提供引用,以便最终用户进行验证;承受能力可以描述为框架告知用户,那些是高风险操作,如 DROP 或 DELETE,以及接受LLM 建议操作后的结果;研究人员称,Panda的反馈组件允许基于 LLM 的调试器接受用户反馈,并在生成响应时考虑这些反馈。 这四个组件构成了调试器的架构,包括问题验证代理(QVA)、训练机制、验证机制、反馈机制和承受机制。 问题验证代理可识别并过滤掉不相关的查询,而训练机制则由文档检索器、Telemetry-2-text和上下文聚合器组成,可为提示或查询提供更多上下文。 研究人员说,验证机制包括答案验证和来源归属,并补充说,所有这些机制以及反馈和承受能力机制都是在利用自然语言进行交互的界面工作。 Panda与 OpenAI 的 GPT-4 对比 AWS研究人员还将 Panda 与 OpenAI 的 GPT-4 模型相比较,后者目前是 ChatGPT 的基础。 研究人员在展示 Aurora PostgreSQL 数据库故障诊断结果时写道:“......用数据库性能查询来提示 ChatGPT,结果往往是'技术上正确'但非常'模糊'或'通用'的建议,通常会被经验丰富的数据库工程师(DBE)认为是无用和不可信的。” 论文显示,在实验中,AWS 研究人员收集了一组具有三种不同能力水平的 DBE,其中大多数人都支持Panda。 此外,研究人员还声称,Panda 虽然在实验中用于云数据库,但可以扩展到任何数据库系统。 |
 商情
商情


