谷歌实现从图片中生成视频,这是否会引发问题?
谷歌实现从图片中生成视频,这是否会引发问题?
作者:开源爱好者
来源:
|
Google VLOGGER能够根据单张照片创建不同长度、高分辨率的视频片段,从微妙的眨眼动作到精准的面部表情和肢体动作,其效果均超越了传统的“说话头像”软件。
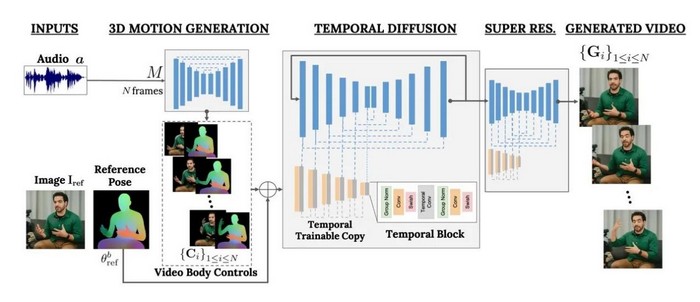
AI社区在制造假动态图像方面已经驾轻就熟——回顾上月推出的OpenAI的Sora,其流畅的虚拟飞行视频令人叹为观止。然而,这也引发了理论与现实层面的双重问题:我们该如何应对这些层出不穷的视频? 本周,谷歌学者Enric Corona与他的团队给出了答案:使用VLOGGER工具来控制这些视频。VLOGGER不仅能够根据单张照片生成人们谈话时的高清视频,更重要的是,它还能根据语音样本为视频注入活力,意味着这项技术能够生成一个受控制的人像视频——一个高清的“化身”。 这一工具可创造出丰富多样的作品。从最基础的层面来看,科罗纳的团队认为VLOGGER将对客服化身产生深远影响,因为更加逼真的合成谈话人物有助于“培养同理心”。他们建议,这项技术能够“为全新的应用场景提供支持,如增强在线沟通、教育或个性化虚拟助手。” 然而,VLOGGER也可能开启深度伪造的新纪元,制作看似真实的人物化身,说出或做出真人从未有过的言行。Corona的团队计划在补充材料中探讨VLOGGER对社会的影响,但这些材料目前在项目的GitHub页面上尚不可见。媒体曾联系Corona询问相关支持材料,但截至发稿时仍未收到回复。 正如其正式论文《VLOGGER:多模态扩散用于化身合成》所述,Corona的团队旨在突破现有化身技术的局限。“制作逼真的人类视频仍然复杂且充满挑战,” Corona的团队写道。 该团队指出,现有的视频化身往往仅展示面部,而将身体和手部省略。而VLOGGER则能够展示完整的躯干以及手部动作。与其他工具相比,VLOGGER在面部表情或姿势方面拥有更丰富的变化,不仅提供基本的唇部同步,更能生成“高分辨率的头部和上半身运动视频……具有相当多样的面部表情和手势”,成为“首个根据语音输入生成说话和移动人类的方法”。 研究团队解释说:“我们在这项工作中追求的目标正是自动化和模拟真实行为:VLOGGER是一个多模态接口,用于体现对话代理,它结合了音频和动画视觉表示,具备复杂的面部表情和日益丰富的身体动作,旨在支持与人类用户的自然对话。”
VLOGGER软件基于左侧的单张照片,巧妙运用“扩散”过程,精准预测出右侧应伴随某人说话声音文件的每一刻视频帧,并生成高清质量的画面。 VLOGGER巧妙融合了深度学习中多个最新趋势,展现了多模态的魔力。这种技术让AI工具能够吸收和合成多种模式,包括文本、音频,以及图像和视频,实现了多感官的交互体验。 大型语言模型,如OpenAI的GPT-4,让自然语言作为输入驱动各类动作成为可能,无论是创建文本段落、谱写歌曲还是绘制图片,都显得轻而易举。 近年来,研究人员通过改进“扩散”技术,找到了众多生成逼真图像和视频的方法。这个源自分子物理学的术语,描绘了物质粒子如何从集中变得分散。在数字领域,信息位也经历了类似的“扩散”,与数字噪声逐渐疏离。 AI扩散技术将噪声引入图像中,通过重建原始图像来训练神经网络,从而掌握构建图像的规则。这种技术为Stable Diffusion和DALL-E等令人瞩目的图像生成过程提供了动力,也是OpenAI在Sora中创建流畅视频的关键。 对于VLOGGER,Corona的团队精心训练了一个神经网络,将说话者的音频与单个视频帧紧密相连。他们结合了一种扩散过程,并利用Transformer这一创新技术,从音频中精确重建视频帧。 Transformer运用注意力机制,根据过往帧和音频来预测视频帧。通过不断预测动作,神经网络学会了逐帧渲染精准的手部和身体动作,以及面部表情,并与音频完美同步。 最后,他们利用第一个神经网络的预测结果,再结合第二个采用扩散技术的神经网络,生成高分辨率的视频帧。这一步骤在数据处理上也是重要的里程碑。 为了制作高清图像,Corona的团队精心编制了MENTOR,一个包含80万个“身份”的视频数据集,全部为人们说话的场景。MENTOR拥有2200小时的视频内容,团队自豪地宣称这是“迄今为止在身份和长度方面使用的最大数据集”,其规模远超先前的其他数据集。 作者们发现,通过一个名为“微调”的后续步骤,可以进一步增强这一过程的效果。在VLOGGER已经在MENTOR上进行“预训练”之后,只需提交一个完整长度的视频,它便能更真实地捕捉一个人头部运动的独特性,如眨眼等细微动作。团队将此过程称为“个性化”,并指出:“通过用更多数据对我们的扩散模型进行微调,针对单个主体的单目视频,VLOGGER可以学习更好地捕捉身份特征,例如当参考图像显示闭眼时。”
VLOGGER的神经网络巧妙融合了两种不同的技术。首先,它通过Transformer的“掩码注意力”机制,根据讲话者的录制音频信号中的声音,预测视频帧中应呈现的姿势。接着,第二个神经网络运用扩散技术,根据首个网络提供的身体运动和表情线索,生成一系列连贯且高质量的视频帧。 VLOGGER引人注目的地方在于,它不仅限于生成视频,就像Sora所实现的功能,它更进一步地将视频与可控制的动作和表情紧密结合,使得生成的逼真视频能够像木偶般被精确操纵。 Corona的团队在论文中明确写道:“我们的目标在于填补近期视频合成工作与可控图像生成方法之间的鸿沟。虽然前者能够生成动态视频,但往往无法控制身份或姿势。” 除了作为语音驱动的化身,VLOGGER还具备强大的编辑功能,允许用户调整说话对象的嘴巴或眼睛等细节。例如,原本频繁眨眼的虚拟人物可以被设定为微眨或不眨,而夸张的大嘴巴说话方式也能被调整为更为细腻的嘴唇动作。
通过实现语音线索对高分辨率视频的控制,VLOGGER开创了全新的视频操纵可能性。这意味着用户可以在视频的每一帧中调整说话者的嘴唇动作,使其与原始源视频截然不同。 尽管VLOGGER在模拟人物方面取得了新的技术突破,但Corona的团队也意识到,如何应对这种技术的潜在滥用问题尚待解决。不难想象,这项技术可能被用于制造政治人物的替身,通过以假视频发表关于核战争等灾难性言论。 未来,我们或许可以期待神经网络在化身技术中扮演更重要的角色,就像电影《银翼杀手》中的“Voight-Kampff 测试”一样,帮助社会分辨出真实的讲话者与逼真的深度伪造者。 |



 商情
商情


